Linguagens de Programação e Banco de Dados
- Python com foco em análise de dados
- Web scraping com Python
- SQL para extração de dados
- Banco de Dados SQLite, Postgres, MySQL, DataGrip, MongoDB
- C / Java
Nessa página, eu demonstro minhas habilidades de resolver problemas de negócio utilizando conceitos e ferramentas da Ciência de Dados, através de projetos com dados públicos.
Você vai encontrar também, minhas experiências profissionais, habilidades, ferramentas, certificações Google Cloud e conceitos envolvendo Ciência de Dados e Engenharia de Software.
Sinta-se à vontade para entrar em contato através dos links no final da página.

Sou estudante do 7 período de Ciência da computação na UFPI e estudo sobre tópicos fundamentais sobre Ciência de dados e Machine Learning.
Atualmente, sou estagiário de Machine Learning na SantoDigital, onde utilizo a Google Cloud Platform (GCP) para desenvolver soluções avançadas de Inteligência Artificial Generativa e Machine Learning para diversos clientes. Minha atuação abrange desde a implementação de modelos preditivos até a criação de pipelines automatizadas para otimizar processos de negócios. Além disso, contribuo significativamente para o nosso produto interno, realizando melhorias contínuas no modelo classificador em produção, garantindo alta precisão e eficiência.
Atualmente, integro um projeto que envolve o Governo do Estado do Piauí, através da Secretaria de Segurança Pública, e a Fundação Cultural e de Fomento à Pesquisa, Ensino, Extensão e Inovação – FADEX. O projeto visa desenvolver soluções para melhorar o gerenciamento e a utilização dos recursos e dados da Secretaria. Utiliza técnicas de Inteligência Artificial (IA), na modalidade Processamento de Linguagem Natural (PLN), para análise de boletins de ocorrência e integração com chatbots nos serviços de atendimento à população.
Para adquirir experiência na solução de problemas de negócio e domínio sobre as ferramentas de análise de dados, constantemente realizo e atualizo projetos já feitos, a fim de potencializar as métricas adotadas no processo.
Entrei como estagiário e, posteriormente, promovido para Engenheiro de Machine Learning na SantoDigital. Durante o dia a dia, utilizo a Google Cloud Platform (GCP) para desenvolver soluções avançadas de Inteligência Artificial Generativa e Machine Learning para diversos clientes. Minha atuação abrange desde a implementação de modelos preditivos até a criação de pipelines automatizadas para otimizar processos de negócios. Além disso, contribuo significativamente para o nosso produto interno, realizando melhorias contínuas no modelo classificador em produção, garantindo alta precisão e eficiência.
Integro um projeto que envolve o Governo do Estado do Piauí, através da Secretaria de Segurança Pública, e a Fundação Cultural e de Fomento à Pesquisa, Ensino, Extensão e Inovação – FADEX. O projeto visa desenvolver soluções para melhorar o gerenciamento e a utilização dos recursos e dados da Secretaria. Utiliza técnicas de Inteligência Artificial (IA), na modalidade Processamento de Linguagem Natural (PLN), para análise de boletins de ocorrência e integração com chatbots nos serviços de atendimento à população.
Comunidade profissional focada em conceitos da área de Ciência de Dados e Machine Learning com o objetivo de desenvolver habilidades analíticas requisitadas no mercado de trabalho.
Correção de provas, exercícios e solução de dúvidas dos alunos.
Construção de soluções de dados para problemas de negócio, próximos dos desafios reais das empresas, utilizando dados públicos de competições de Ciência de Dados, onde eu abordei o problema desde a concepção do desafio de negócio até a publicação do algoritmo treinado em produção, utilizando ferramentas de Cloud Computing.

Projeto idealizado com o objetivo de desenvolver um modelo de Machine Learning de Regressão capaz de realizar a previsão de vendas pelas próximas 6 semanas da rede de farmácias Rossmann, de modo que o CFO provisione o valor que será investido por cada unidade de loja em um futuro processo de reforma. Como resultado final, tivemos umas predição do valor de venda de R$ 286,988,384.00 podendo variar entre R$ 287,742,483.83 ( Melhor cenário ) e R$ 286,234,315.47 ( Pior cenário ).

Projeto idealizado com o objetivo de desenvolver um modelo de Machine Learning de Classificação capaz de realizar a previsão do churn dos clientes da empresa TopBank, de modo que haja a maximização do ROI ( Return on Investiment ) por meio de estratégias estabelecidas após a análise profunda do problema. Como resultado final, obtivemos um valor de lucro, como média entre os cenários analisados, de R$ 2.785.202,00, o que representa um ROI de 361%.

Nesse projeto, uma empresa de comunicação nomeada como BuzzFeed busca maneiras de realizar o diagnóstico de sarcasmo em suas manchetes de notícias, de modo a evitar possíveis desentendimentos dos leitores em algumas manchetes sarcásticas. Para cumprir o objetivo, foi utilizado técnicas de Processamento de Linguagem Natural (PLN) e Machine Learning, como o Word2Vec Embedding e Redes Neurais Recorrentes LSTM Bidirecionais. O modelo final escolhido apresentou excelentes métricas, como uma acurácia e AUC de 83%. Ademais, a consulta para detecção de títulos sarcásticos pode ser feita via Streamlit.
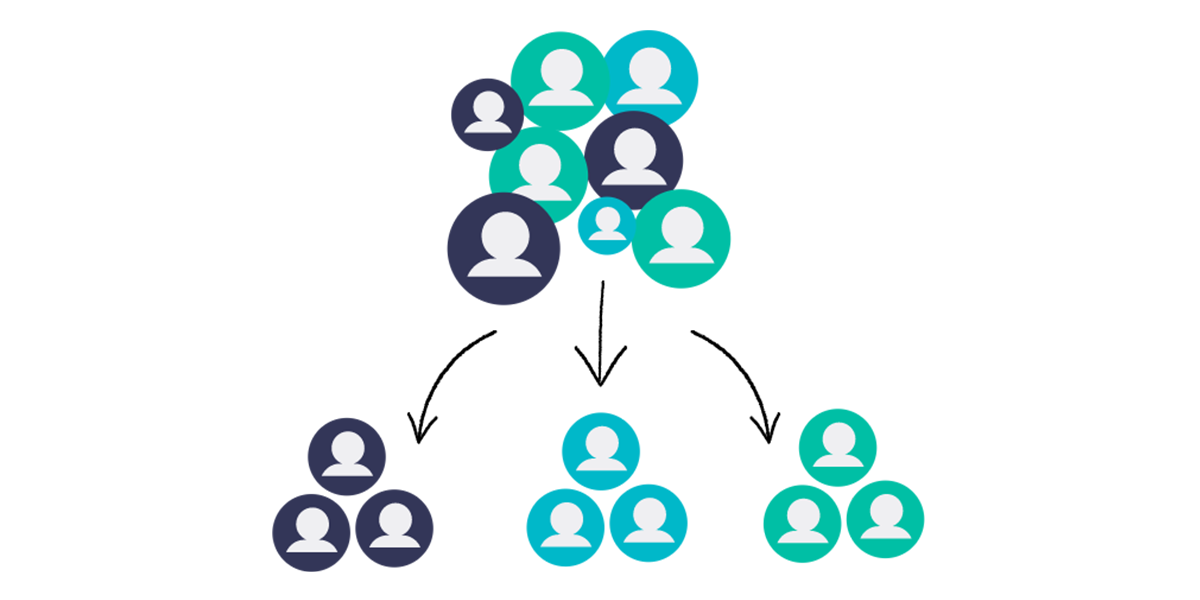
Projeto realizado com o foco na determinação do grupo de clientes mais relevantes financeiramente para um e-commerce de acordo com as definições modelo RFM. Nesse sentido, foram utilizados diversas técnicas de Clusterização em Machine Learning. Os produtos de dados desenvolvidos foram uma lista com a dados de todos os clientes e seus clusters, um relatório com questões abordadas pelo time de marketing e um dashboard no Metabase alimentado com dados atualizados através de serviços da AWS. A solução desenvolvida apresenta um grupo, formado por 7,2% da base de clientes, que detem 40,20% do faturamento total da empresa, e um faturamento médio de $15.332.

Projeto com objetivo de construir um sistema de recomendação de livros baseado no comportamento e preferências de cada usuário no que diz respeito ao histórico de compras e interações com livros. Foi utilizado técnicas de recomendação e Machine Leaning, como NearestNeighbours e Cossine Similarity. O modelo final escolhido foi a técnica de similaridade de cossenos, por ser mais simples ( não requer treinamento ) e apresentar alta eficiência computacional. A visualização de nomes e imagens de livros recomendados pode ser vista via Streamlit.

Projeto idealizado com o objetivo de ajudar uma empresa de seguros de saúde no ranqueamento dos principais clientes em potencial para comprar um novo tipo de seguro para a empresa ( carro ) e, portanto, fazer um Cross-Sell. Para tanto, foi utilizado técnicas de Machine Learning e Learn to Rank, de modo que seja possível a consulta de uma lista de clientes com maior probabilidade de adquirir o seguro de carro via Google Sheets, facilitando a estratégia de comunicação da empresa e otimizando seu negócio. Por fim, decidiu-se por fazer ligações apenas para uma parte da base de clientes com maior propensão de compra ( 46% ) e o lucro total foi de R$3.878.010,00, o que representa uma solução 1.44 vezes melhor do que ligar para 100% da base.

Projeto idealizado com o objetivo de estudar o conceito de elasticidade de preços e, portanto, a profunda relação entre demanda e preço dos produtos. Nesse sentido, foi desenvolvido um modelo de Machine Learning relacionado à regressão linear, capaz de prever o quanto é aceitável aumentar/diminuir o valor dos produtos, impactando a demanda, para tentar saber se conseguiríamos aumentar a receita. A visualização dos possíveis cenários após um desconto ou aumento no preço podem ser visualizados via Streamlit.

Nesse projeto, os conceitos de Programação em python, manipulação de dados, pensamento estratégico e lógica de negócio, junto com ferramentas de desenvolvimento web como o Streamlit e Github, foram usados para desenvolver um painel gerencial com as principais métricas de uma empresa de marketplace de comida. O resultado final do projeto foi um painel hospedado em um ambiente Cloud que auxilia o CEO nas possíveis tomadas de decisão por meio de insights gerados a partir da análise. O projeto é disponibilizado através de um link. O painel pode ser acessado por qualquer dispositivo conectado na internet.
Nesse projeto, desenvolvi uma aplicação web utilizando Streamlit, focada em fornecer uma experiência completa para entusiastas de games. A aplicação foi construída com uma stack que inclui Python, Streamlit e frameworks para manipulação de LLMs, como o LangChain. O principal produto desenvolvido foi um chatbot com Gen AI e RAG, capaz de responder dúvidas e fornecer recomendações sobre os jogos mais populares na Steam. A aplicação também integra análise de sentimento utilizando modelos pré-treinados para avaliar as reviews dos usuários. Além disso, o projeto inclui funcionalidades de registro de reviews, consulta de notícias atualizadas sobre o mundo dos games, e um sistema seguro de login/registro com armazenamento de dados no banco de dados PostgreSQL, garantindo uma experiência fluida e integrada para os usuários.

Neste projeto, desenvolvi uma pipeline para desenvolvimento de um modelo preditivo capaz de estimar os preços de casas em Paris, utilizando uma abordagem baseada em machine learning. A aplicação foi construída utilizando Python e frameworks como Scikit-Learn, PyCaret, Pandas e KubeFlow para manipulação de dados e desenvolvimento do modelo. A pipeline de machine learning foi projetada para processar dados históricos de preços, características dos imóveis e dados demográficos, visando prever o valor de mercado das propriedades. O modelo foi treinado e otimizado para alcançar alta acurácia, alcançando excelentes valores em métricas como MAE, MSE e R2. Além disso, foi implementado um fluxo de CI/CD para treinamento contínuo do modelo, utilizando serviços do Google Cloud Platform como Cloud Functions para garantir a escalabilidade e a disponibilidade do serviço.
Sinta-se a vontade para entrar em contato